Multi-node/Multi-gpus Data analytics with RAPIDS
Dask-RAPIDS is a powerful integration between Dask and RAPIDS that enables scalable, GPU-accelerated data processing across multiple GPUs and nodes.
On one hand, RAPIDS provides GPU-accelerated versions of pandas, NumPy, and scikit-learn (e.g., cuDF, cuML, cuGraph). On the other hand, Dask provides a distributed computing framework that allows you to run these RAPIDS components in parallel across many GPUs.
Together, Dask-RAPIDS enables:
-
Processing terabyte-scale data on multi-GPU or multi-node clusters
-
Familiar pandas/scikit-learn-style APIs, backed by GPU speed
-
Real-time performance monitoring via Dask Dashboard
The tight integration with CuPy, dask_cudf, dask_cuda, and UCX (for fast GPU communication) is ideal for interactive data science, big data processing, and building GPU-accelerated ML pipelines.
Starting a multi-node/multi-gpus Dask-RAPIDS cluster
- The following launcher script requests the allocation of 2 GPU nodes for a total of 8 GPUs
- Once resources are allocated, we setup the different UCX transports to enable fast communication between all GPUs
- We start the dask scheduler on the first allocated node
- We then spawn as many dask cuda workers as GPUs
#!/bin/bash -l
#SBATCH --job-name=Dask-Rapids-Cluster
#SBATCH --account=p20xxxx
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=4
#SBATCH --cpus-per-task=16
#SBATCH --gpus-per-task=1
#SBATCH --time=01:00:00
#SBATCH --qos=default
#SBATCH -p gpu
module --force purge
module load env/release/2024.1
module load RAPIDS
export SCHEDULER_FILE="scheduler_${SLURM_JOB_ID}.json"
export NODES=$(scontrol show hostnames)
export DASK_LOGGING__DISTRIBUTED=info
export DASK_DISTRIBUTED__COMM__UCX__CREATE_CUDA_CONTEXT=True
export UCX_MEMTYPE_REG_WHOLE_ALLOC_TYPES=cuda
export DASK_DISTRIBUTED__COMM__UCX__CUDA_COPY=True
export DASK_DISTRIBUTED__COMM__UCX__TCP=True
export DASK_DISTRIBUTED__COMM__UCX__NVLINK=True
export DASK_DISTRIBUTED__COMM__UCX__INFINIBAND=True
export DASK_DISTRIBUTED__COMM__UCX__RDMACM=True
# Start controller on this first task
dask-scheduler --scheduler-file ${SCHEDULER_FILE} --interface "ib0" --protocol "ucx" &
sleep 5
for NODE in ${NODES}; do
echo "Starting ${SLURM_NTASKS_PER_NODE} workers on ${NODE}"
for (( GPU_ID=1; GPU_ID<=${SLURM_NTASKS_PER_NODE};GPU_ID++ )); do
srun --export=ALL,UCX_MEMTYPE_REG_WHOLE_ALLOC_TYPES=cuda,CUDA_VISIBLE_DEVICES=$(( ${GPU_ID}-1 )) \
--cpu-bind=core -N 1 -n 1 -c ${SLURM_CPUS_PER_TASK} -w ${NODE} dask cuda worker --scheduler-file ${SCHEDULER_FILE} \
--nthreads=${SLURM_CPUS_PER_TASK} --scheduler-file ${SCHEDULER_FILE} --interface "ib0" --protocol "ucx" --enable-tcp-over-ucx \
--enable-nvlink --enable-infiniband --enable-rdmacm --rmm-pool-size "35GB" --rmm-maximum-pool-size "39GB" --death-timeout 3600 &
done
done
python "$@"
- This python script first connects the dask-rapids cluster using the environment variable
SCHEDULER_FILE - Then, a cudf dataframe with 100 millions rows is generated
- The cudf dataframe is partionned between all 8 GPUs
- We perform some operations on it as it could be done with pandas except that we use 8 GPUS with a total of 320GB of device memory
import dask
import cupy as cp
import cudf
import dask_cudf
from dask_cuda import LocalCUDACluster
from dask.distributed import Client, wait
import matplotlib.pyplot as plt
import time
import os
client = Client(scheduler_file=os.environ['SCHEDULER_FILE'])
print("Creating synthetic distributed GPU data...")
n_rows = 100_000_000 # 100 million rows
n_parts = len(client.has_what()) # one partition per worker/GPU
# Create a Dask-cuDF DataFrame
ddf = dask_cudf.from_cudf(
cudf.DataFrame({
'x': cp.random.rand(n_rows),
'y': cp.random.rand(n_rows),
'label': cp.random.choice([10,100,1000], n_rows)
}),
npartitions=n_parts
)
ddf = ddf.persist()
wait(ddf)
print("DataFrame ready with", ddf.npartitions, "partitions")
print("Performing operations (mean, groupby)...")
start = time.time()
mean_x = ddf['x'].mean().compute()
grouped = ddf.groupby('label').y.mean().compute()
print("Mean of x:", mean_x)
print("Grouped y mean:\n", grouped)
print("Completed in", time.time() - start, "seconds")
print("Plotting a GPU-based scatter sample...")
sample = ddf.sample(frac=0.001).compute().to_pandas()
plt.scatter(sample['x'], sample['y'], alpha=0.3)
plt.title("Sampled GPU-parallel data")
plt.xlabel("x")
plt.ylabel("y")
plt.show()
print("Applying CuPy UDF per partition")
def cupy_sigmoid(col):
return 1 / (1 + cp.exp(-col))
def apply_sigmoid(df):
df['sigmoid_x'] = cupy_sigmoid(df['x'].values)
return df
sig_ddf = ddf.map_partitions(apply_sigmoid)
sig_ddf = sig_ddf.persist()
wait(sig_ddf)
print(sig_ddf.head())
# Done
print("All tasks complete!")
- To execute the previous code, just use
sbatch submit-rapids-job.sh dask-rapids.pyon a login node. - Make sure to replace
<ACCOUNT>by your account on the platform in the preamble ofsubmit-rapids-job.sh
Dask Dashboard Overview
The Dask Dashboard is a web-based monitoring tool that provides real-time insights into the performance and status of a Dask cluster. It helps users understand how tasks are distributed, how resources are utilized, and where potential bottlenecks exist. The dashboard is particularly useful for debugging, performance tuning, and optimizing parallel workloads. 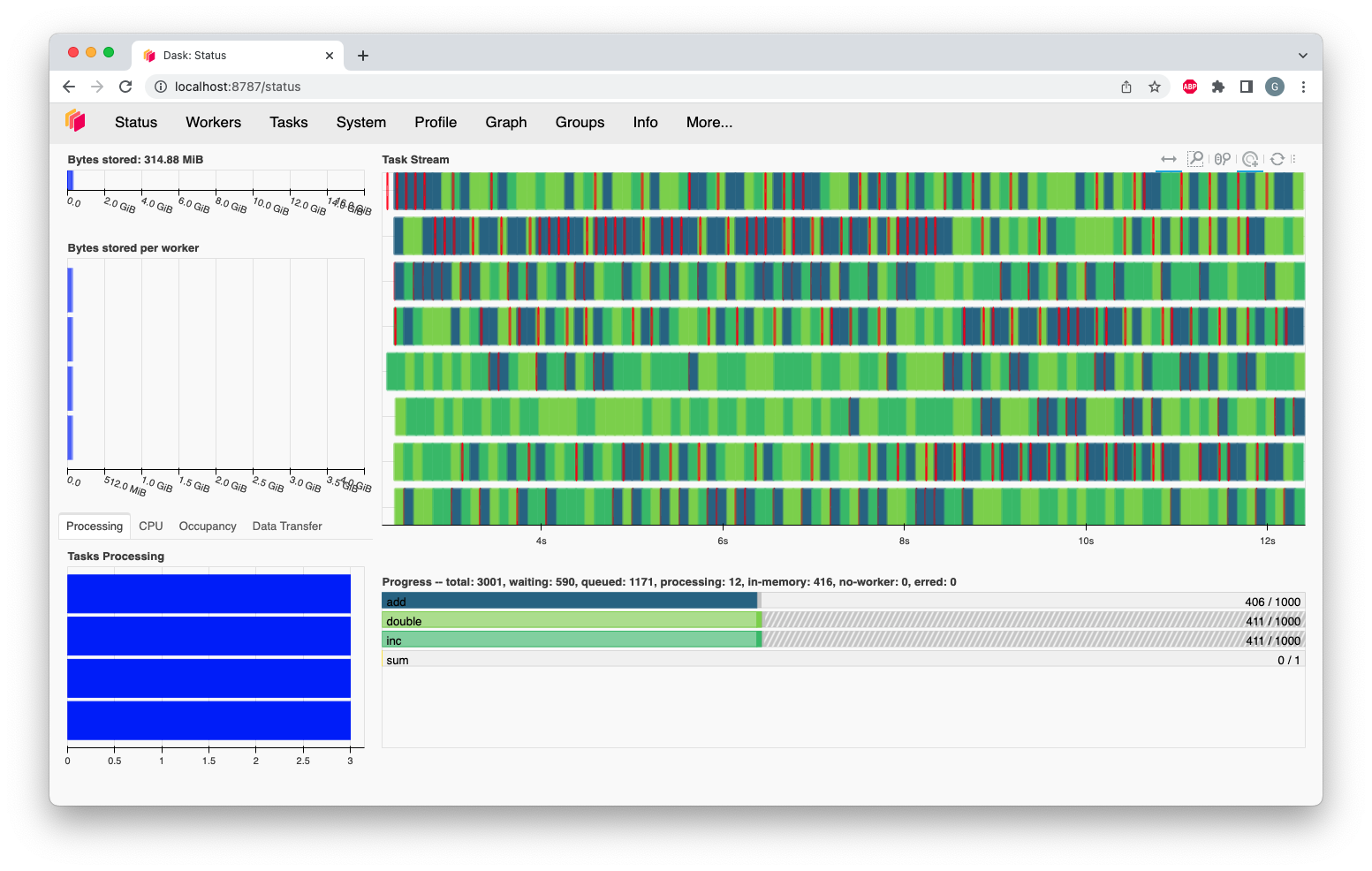
-
To access the Dask dashboard, you will need to create a ssh tunnel and to do this, you need to follow the following steps:
-
In the python script you are launching (
dask-rapids.pyin this example), add the following commandprint(client.dashboard_link) - Retrieve the output of the previous command (in the job stdout) and open a new terminal on your local machine
- Enter the following command:
ssh -p 8822 -NL 8787:XX.XX.XX.XX:8787 <user>@login.lxp.luby replacing XX.XX.XX.XX with the ip address obtained above