Compiling
Compiling C, C++, and Fortran code on MeluXina is similar to how it is done on regular personal systems, with some differences.
One compiler suite on MeluXina is the AMD Optimizing C/C++ Compiler (AOCC), providing clang, clang++, and flang frontends.
Other compilers are available such as the Intel suite, providing icc, icpc, and ifort.
The GNU Compiler Collection is also available on MeluXina, providing gcc, g++, and gfortran. GNU compiler compatibility is ubiquitous across free and open-source software projects, which includes much scientific software.
Generic compilation steps
A generic workflow must be followed to compile any source code or software on your own. After reserving a node on MeluXina, go to the directory with your code sources. We recommend temporarily placing your sources and compiling under the $SCRATCH directory where you will get better performance.
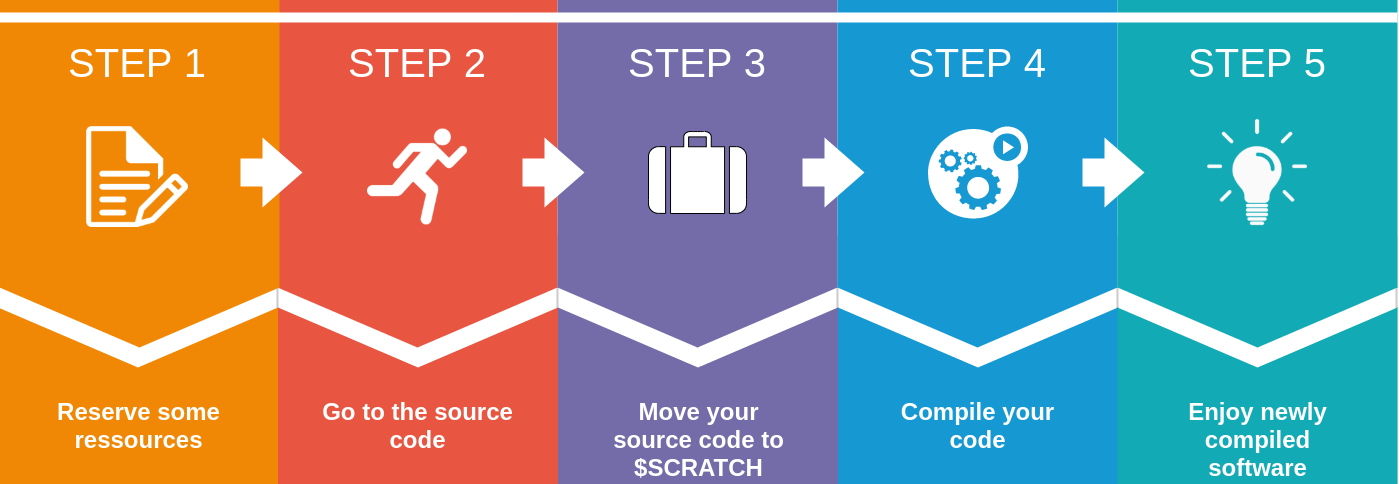
Using command-line
From serial code to parallel OpenMP and MPI code the different step to compile a source code are detailed in the following for different languages such as C, C++ and Fortran
Serial
Source code
1 2 3 4 5 6 7 | |
Compiling and Executing
On a reserved node
module load foss/2023a
gcc -o helloworld helloworld.c
./helloworld
Output
Output from the execution
Hello world!
1 2 3 4 5 6 7 | |
Compiling and Executing
On a reserved node
module load foss/2023a
g++ -o helloworld helloworld.cpp
./helloworld
Output
Output from the execution
Hello world!
1 2 3 | |
Compiling and Execting
On a reserved node
module load foss/2023a
gfortran -o helloworld helloworld.f
./helloworld
Output
Output from the execution
Hello world!
OpenMP
There are a variety of technologies available that can be used to write a parallel program and some combination of two or more of these technologies. While the clusters are capable of running programs developed using any of these technologies, The following examples tutorial will focus on the OpenMP and Message Passing Interface (MPI) compilation
Source code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Compiling and Executing
On a reserved node
module load foss/2023a
gcc -o helloworld_omp helloworld_OMP.c -fopenmp
export OMP_NUM_THREADS=8
./helloworld_omp
Output
Output from the execution
Hello World... from thread = 0
Hello World... from thread = 6
Hello World... from thread = 7
Hello World... from thread = 3
Hello World... from thread = 5
Hello World... from thread = 2
Hello World... from thread = 1
Hello World... from thread = 4
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Compiling and Executing
On a reserved node
module load foss/2023a
g++ -o helloworld_omp helloworld_OMP.cpp -fopenmp
export OMP_NUM_THREADS=8
./helloworld_omp
Output
Output from the execution
Hello World... from thread = 0
Hello World... from thread = 2
Hello World... from thread = 6
Hello World... from thread = 4
Hello World... from thread = 7
Hello World... from thread = 3
Hello World... from thread = 5
Hello World... from thread = 1
1 2 3 4 5 6 7 8 9 10 | |
Compiling and Executing
On a reserved node
module load foss/2023a
gfortran -o helloworld_omp helloworld_OMP.f -fopenmp
export OMP_NUM_THREADS=8
./helloworld_omp
Output
Output from the execution
Hello World... from thread = 3
Hello World... from thread = 0
Hello World... from thread = 2
Hello World... from thread = 6
Hello World... from thread = 1
Hello World... from thread = 4
Hello World... from thread = 7
Hello World... from thread = 5
Message Passing Interface (MPI)
MPI is the technology you should use when you wish to run your program in parallel on multiple cluster compute nodes simultaneously. Compiling an MPI program is relatively easy. However, writing an MPI-based parallel program takes more work.
Source code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Compiling and Executing
On a reserved node
module load foss/2023a
mpicc -o helloworld_mpi helloworld_MPI.c
srun -n 4 ./helloworld_mpi
Output
Output from the execution
hello world from process 1 of 4
hello world from process 2 of 4
hello world from process 0 of 4
hello world from process 3 of 4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Compiling and Executing
On a reserved node
module load foss/2023a
mpic++ -o helloworld_mpi helloworld_MPI.cpp
srun -n 4 ./helloworld_mpi
Output
Output from the execution
hello world from process 2 of 4
hello world from process 3 of 4
hello world from process 1 of 4
hello world from process 0 of 4
1 2 3 4 5 6 7 8 9 10 | |
Compiling and Executing
On a reserved node
module load foss/2023a
mpifort -o helloworld_mpi helloworld_MPI.f90
srun -n 4 ./helloworld_mpi
Output
Output from the execution
hello world from process 2 of 4
hello world from process 3 of 4
hello world from process 1 of 4
hello world from process 0 of 4
Compiling for MeluXina FPGAs
The MeluXina Accelerator Module includes a partition with FPGA accelerators. Please clone first the oneAPI-sample repository with the git clone --depth=1 https://github.com/oneapi-src/oneAPI-samples.git in your home folder.
-
As you can see Intel provides numerous code samples and examples to help your grasping the power of the oneAPI toolkit.
-
We are going to focus on
DirectProgramming/C++SYCL_FPGA. -
Create a symbolic at the root of your home directory pointing to this folder:
ln -s oneAPI-samples/DirectProgramming/C++SYCL_FPGA/Tutorials/GettingStarted
-
The fpga_compile folder provides basic examples to start compiling SYCL C++ code with the DPC++ compiler
-
The fpga_recompile folder show you how to recompile quickly your code without having to rebuild the FPGA image
-
The fpga_template is a starting template project that you can use to bootstrap a project
Before targeting a specific hardware accelerator, you need to ensure that the sycl runtime is able to detect it.
Commands
1 2 3 4 5 6 7 8 9 | |
Output
[opencl:cpu:0] Intel(R) OpenCL, AMD EPYC 7452 32-Core Processor 3.0 [2022.13.3.0.16_160000]
[opencl:acc:1] Intel(R) FPGA Emulation Platform for OpenCL(TM), Intel(R) FPGA Emulation Device 1.2 [2022.13.3.0.16_160000]
[opencl:acc:2] Intel(R) FPGA SDK for OpenCL(TM), p520_hpc_m210h_g3x16 : BittWare Stratix 10 MX OpenCL platform (aclbitt_s10mx_pcie0) 1.0 [2022.1]
[opencl:acc:3] Intel(R) FPGA SDK for OpenCL(TM), p520_hpc_m210h_g3x16 : BittWare Stratix 10 MX OpenCL platform (aclbitt_s10mx_pcie1) 1.0 [2022.1]
-
If you see the same output, you are all setup.
-
Full compilation can take hours depending on your application size. In this context, emulation and static report evaluation are keys to succeed in FPGA programming
-
This phase produces the actual FPGA bitstream, i.e., a file containing the programming data associated with your FPGA chip. This file requires the target FPGA platform to be generated and executed. For FPGA programming, the Intel® oneAPI toolkit requires the Intel® Quartus® Prime software to generate this bitstream.
Full hardware compilation
$ icpx -fsycl -fintelfpga -qactypes -Xshardware -Xsboard=p520_hpc_m210h_g3x16 -DFPGA_HARDWARE vector_add.cpp -o vector_add_report.fpga
-
The compilation will take several hours. Therefore, we strongly advise you to verify your code through emulation first.
-
You can also use the
-Xsfast-compileoption which offers a faster compile time but reduce the performance of the final FPGA image.
Note
If you need more information regarding our FPGA hardware and how to program them, please get in touch via our service desk.