System overview
MeluXina is designed as a modular system, providing facilities for HPC, HPDA and AI workloads. The following architecture diagram gives an overview of the different modules and how they are interconnected.

From a user perspective three main types of modules exist: computing modules, storage modules and user interface modules.
| Module type | Module | Short Description |
|---|---|---|
| User Interface | System | The System Module provides login nodes allowing Linux command line interface for users to mainly monitor accounts, launch jobs and transfer/manage data |
| Cloud | Temporary or persistent services deployed through Virtual Machines, accessible publicly or from MeluXina computational modules | |
| Compute | Cluster | Nodes with high core-count CPUs for job processing |
| Accelerator (GPU) | Nodes with CPUs and 4 GPU-AI accelerators for processing jobs that can take advantage of an increased level of parallelism | |
| Accelerator (FPGA) | Nodes with CPUs and 2 FPGA cards for specialized workloads | |
| Large Memory | Nodes with high core-count CPUs and an increased amount of RAM for processing memory-intensive jobs | |
| Storage | Scratch (Tier1) | Extremely fast Lustre storage meant for temporary data staging when access speed is critical for the computational workload |
| Project (Tier2) | Fast, permanent Lustre storage hosting user home directories and project data | |
| Backup (Tier3) | Lustre storage meant for data backup | |
| Archive | Long term and slower archiving solution for long-term data retention |
User interface modules
The user interface modules are the entry point for users to take advantage of the resources offered by other modules. More generally, they are the interface between MeluXina and the outside world.
Login nodes
The main access to MeluXina is provided through its 4 login nodes. Each of them is composed of 2 AMD Rome CPUs (32-core @ 2.35 GHz, with Hyper-threading enabled - thus 128HT cores/node) and has 512 GB of memory. These nodes have access to the Scratch and Project data tiers through the high-speed InfiniBand network.
Login nodes are typically accessed through a command line interface (SSH) and allow the user to perform various tasks such as transferring data (SFTP), launching and managing jobs (Slurm scheduler).
To learn how to use login nodes, please read the first steps page.
Cloud module
The Cloud module is composed of 20 cloud VM host nodes and dedicated Ceph storage. Each cloud node is composed of 2 AMD Rome CPUs (64 core @ 2.6 GHz, with Hyper-threading enabled - thus 256HT cores/node) and has 512 GB of memory.
Additionally, 5 cloud GPU nodes have been added to the cloud module. 4 cloud GPU nodes are composed of 2 AMD Turyn CPUs (32 core @ 2.6 GHz, with Hyper-threading enabled - thus 128 threads/node) with 768 GB of memory and 2 NVidia NVL H200 (141 GB of ram each). 1 cloud GPU nodes is equipped with 2.3TB of memory and 8 Nvidia H200 NVL GPUs.
They are intended to provide services at a higher-level than login nodes, e.g. through web services (portals, APIs).
Compute modules
Slide to see all specifications:
| Compute Module | #Nodes | Type | CPU | Accelerator | RAM | Disk | Interconnect | Total #Cores | Total #SMs | Total #TensorCore/GPU | Int/FP32 Cuda cores/SM | Total RAM | Theoretical perf. | HPL Perf. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cluster | 573 | XH2000 (DLC) | 2x AMD EPYC Rome 7H12 64c @ 2.6GHz | - | 512GB | - | 1xHDR200 SP | 73344 | - | - | - | 293TB | >3PFlops | >2PFlops |
| Accelerator - GPU | 200 | XH2000 (DLC) | 2x AMD EPYC Rome 7452 32c @2.35GHz | 4x NVIDIA Ampere 40GB HBM | 512GB | 1.92TB SSD | 2xHDR200 SP, dual-rail | 12800 | 86400 | 432 | 64 | 102TB | >15PFlops / ~500PFlops 'AI' | >=10PFlops |
| Accelerator - FPGA | 20 | X430-A5 | 2x AMD EPYC Rome 7452 32c @2.35GHz | 2x Intel Stratix 10MX 16GB HBM | 512GB | 1.92TB SSD | 1xHDR200 DP, dual-rail | 1280 | - | - | - | 10TB | ||
| Large Memory | 20 | X430-A5 | 2x AMD EPYC Rome 7H12 64c @ 2.6GHz | - | 4096GB | 1.92TB SSD | 1xHDR200 DP, dual-rail | 2560 | - | - | - | 80TB |
Cluster module (CPU nodes)
The cluster module is composed of 573 nodes. Each node has 2 AMD Rome CPUs, each with 64 cores @ 2.6 GHz for a total of 128 cores (256HT cores), and has 512 GB of RAM. These nodes are connected to the InfiniBand network.
These are traditional HPC nodes, with state-of-the-art hardware, and are designed to offer great performance for the majority of workloads.
Accelerator module (GPU nodes)
200 GPU nodes are part of the Accelerator Module, each featuring 2 AMD Rome CPUs (32 cores @ 2.35 GHz - 128HT cores total) and 4 NVIDIA A100-40 GPUs. These nodes have 512 GB of RAM, a local SSD of 1.92 TB and 2 HDRcards connecting them to the InfiniBand network.
For workloads exhibiting a strong data parallelism, these nodes provide a significant improvement in terms of computing speed. To take advantage of their capabilities, the software should have been ported or written specifically.
The MeluXina User Software Environment maintains a rich set of GPU-AI accelerated applications, a list of highlighted tools can be seen here.
Accelerator module (FPGA nodes)
There are 20 FPGA (Field Programmable Gate Arrays) nodes. Each node is composed of 2 AMD Rome CPUs (32 cores @ 2.35 GHz each, 128HT cores total) and of 2 Intel Stratix 10MX 16 GB FPGA. These nodes have 512 GB of RAM, and a local SSD of 1.92 TB.
FPGA are configurable processors and are mostly used when a highly customized solution is required to obtained good performances. To take advantage of these nodes, the user software must be ported or written specifically.
Large Memory module
Large memory nodes are similar to regular CPU nodes, but offering a larger RAM for particularly demanding workloads. Each large memory node is composed of 2 AMD Rome CPUs (64 core @ 2.6 GHz, 256HT cores total), has 4 TB of memory (4096 GB) and 1.92 TB of local storage. These nodes have access to both the InfiniBand and the ethernet network.
Optimizing resources
For some workloads, it is important to have larger than usual RAM to avoid spurious and costly disk accesses. If the CPU nodes in the Cluster Module cannot accommodate a particular workload, e.g. an application cannot take advantage of distributed memory, Large Memory nodes may be required.
Storage modules
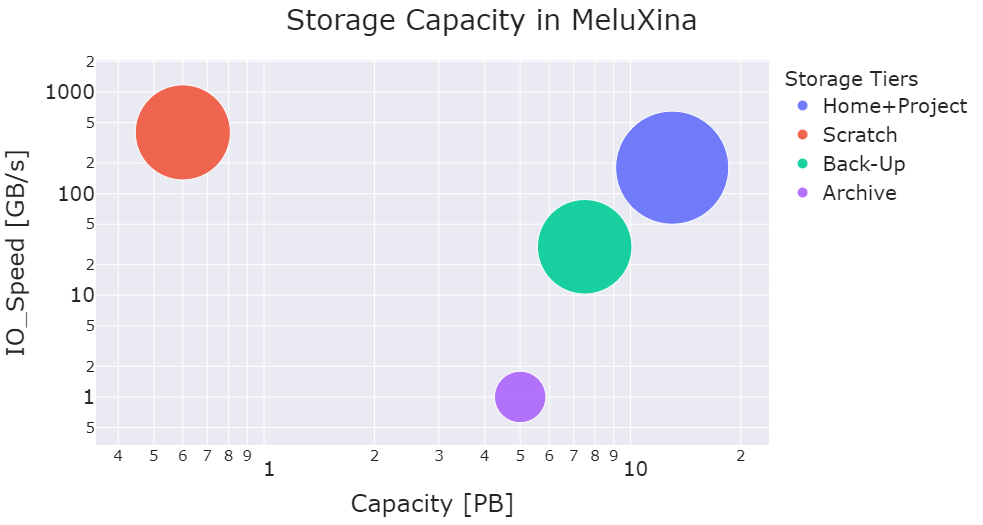
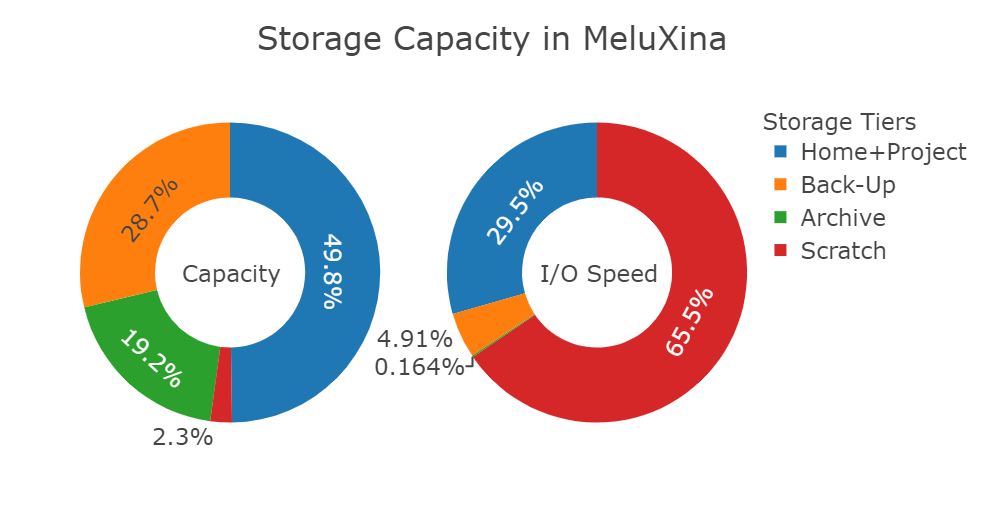
| Storage Tier | Data | Meta-Data | Net Capacity [PB] | Filesystem | IO Speed [GB/s] |
|---|---|---|---|---|---|
| Scratch (Tier1) | EXAScaler 400NVX | <- | 0.6 | Lustre | 400 |
| Project (Tier2) | EXAScaler 7990X | SFA400NVXE | 12 | Lustre | 180 |
| Backup (Tier3) | EXAScaler 7990X | SFA400NVXE | 6.7 | Lustre | 30 |
| Archive (Tape) | - | - | 5 | LTFS | - |
MeluXina Storage Capabilities. Click for Interactive version
Scratch (Tier1)
This data tier provides 0.5 PB of temporary Lustre storage and has a bandwidth over 400 GB/s. This storage can be used when a job needs some extra bandwidth to either read or write data. Projects can use it as a staging area. It is not meant to be used as permanent (project-length) storage, data should not be kept permanently there. Data should be moved back to the Project data tier and temporary files cleaned up regularly.
Project (Tier2)
This data tier has over 12 PB of Lustre storage and throughput over 180 GB/s. This is the core storage for projects and user home directories. User home directories belong to a single user, while project directories are meant for sharing files across different users participating in the same project.
Data privacy and security
By default, only a user is allowed to see and manipulate the content of the corresponding home folder. Similarly, only users members of a project are allowed to see the content of the project folder(s). It is prohibited to modify the rights of these folders.
Backup & Archive
The Backup data tier provides over 6.7 PB of storage and is meant to provide redundancy of specific data in case of accidental removal or overwrites.
The Archive data tier provides 5 PB of tape-based storage. This archive system physically separate from the main MeluXina compute and storage Modules.
The tape archive is intended for long-term retention of important data, as part of data backup workflows (i.e. not meant as storage for data in use by computing workflows).
Project owners and project managers may request data to be backed up on the Backup or Archive tiers for the duration of their projects.